Ember Octane has landed along with a large number of new features, but none of these features is more exciting to me personally than autotracking. Autotracking is Ember’s new reactivity system, which is what allows Ember to know when stateful values (such as @tracked properties) have changed. This was a massive update under the hood, and involved completely rewriting some of Ember’s oldest abstractions on top of this new core.
Autotracking is, at first glance, very similar to Ember Classic’s reactivity model (based on computed properties, observers, and Ember.set()). If you compare the two side by side, the main difference seems to be where the annotations are placed. In Octane you decorate the properties that you depend on, while in Classic you decorate the getters and setters.
class OctaneGreeter {
@tracked name = 'Liz';
get greeting() {
return `Hi, ${this.name}!`;
}
}
class ClassicGreeter {
name = 'Liz';
@computed('name')
get greeting() {
return `Hi, ${this.name}!`;
}
}But if you were to dig deeper you’d find that autotracking is quite a lot more flexible and powerful. For instance, you can autotrack the results of functions, which was something that was impossible in Ember Classic. Take this model for a simple 2d video game, for example:
class Tile {
@tracked type;
constructor(type) {
this.type = type;
}
}
class Character {
@tracked x = 0;
@tracked y = 0;
}
class WorldMap {
@tracked character = new Character();
tiles = [
[new Tile('hills'), new Tile('beach'), new Tile('ocean')],
[new Tile('hills'), new Tile('beach'), new Tile('ocean')][
(new Tile('beach'), new Tile('ocean'), new Tile('reef'))
],
];
getType(x, y) {
return this.tiles[x][y].type;
}
get isSwimming() {
let { x, y } = this.character;
return this.getType(x, y) === 'ocean';
}
}We can see that the isSwimming getter would update whenever character changed position (x/y coordinates). But it would also update whenever the tile that getType returned updated, keeping the system in sync . This type of dynamism popped up from time to time when working with CPs, without any great solutions. It usually required adding many intermediate values to calculate the derived state .
The point being, autotracking is pretty fundamentally different from Ember Classic. This is great, and exciting! But it’s also a bit confusing, because many of the patterns that Ember developers have learned over the years don’t work as well in Octane.
This is why I’ve decided to start a new blog post series on autotracking, discussing the design behind autotracking as a system. This series will show how to use autotracking in different ways for a variety of use cases. I’ll say up front that these blog posts are not meant to be comprehensive. The goal is to setup the mental model for how autotracking works under the hood, and how to build patterns and libraries that work with it.
So far I have 7 posts planned. The first few will be introductory posts discussing the “big picture”, and the rest will be case studies dealing with the nitty-gritty:
As we go along I’m hoping to add more case studies for interesting or difficult cases that new Octane users encounter. So, if you have anything that you’d like me to dig into as part of this series, let me know! You can reach out to me via email or on Discord.
Now then, let’s get on to our first topic: What is “reactivity”?
Reactivity in Plain English
Reactivity, or “reactive programming”, is one of those buzz words that has been thrown around a lot in the past decade or so. It has been applied to many different contexts, and is a very broad concept, so it can be hard to try to distill down exactly what it means. But, I’m going to try 😄
Reactivity: A declarative programming model for updating based on changes to state.
Note that I’m defining the term “reactivity” directly, rather than “reactive programming” or “reactivity model”. In common conversation, I find that we tend to refer to “Ember’s reactivity” or “Vue’s reactivity”, so I think it makes sense as a noun itself in the context of programming. In the end, all these terms essentially mean the same thing.
So, we have a definition that fits into a sentence! So far so good, I think we’re beating Wikipedia here.
But now we have two more terms that our definition is based on that are possibly equally hazy to many: “declarative” and “state”. What do we mean by “declarative programming”, and how does it differ from other styles such as “imperative” and “functional” programming? And what exactly is “state”? We talk a lot about it in the programming world, but it can be hard to find a down-to-earth definition, so let’s dig in.
State
“State” is in a lot of ways a fancy term for “variables”. When we refer to the state of the program, we refer to any of the values that can change within it; that is, any values that aren’t static. In JavaScript, state exists as:
- Variables declared with
letandconst - Properties on objects
- Values within arrays or other collections, such as maps and sets
These are forms of what I’ll call root state, meaning that they represent real, concrete values in the system. By contrast, there is also derived state, which is state that is produced by combining root state. For instance:
let a = 1;
let b = 2;
function aPlusB() {
return a + b;
}In this example, aPlusB() returns a new value that is derived from the value of a and b. Calling the function does not introduce any local variables or values, so it does not have any of its own root state. This is an important distinction, because it means that if we know the value of a and the value of b, then we also know the value of aPlusB(). We also know that if a or b changes, then aPlusB() will also change, which is crucial for building a reactive system.
Declarative Programming
You may have heard the terms “imperative”, “declarative”, and “functional” tossed around before when talking about various styles of programming, but it can be difficult to know exactly what the difference is between them. Fundamentally, it comes down to this distinction:
In declarative programming, the programmer describes what they want to happen, without worrying about the details of how it is done.
In imperative programming, the programmer describes the exact steps for how something should be done.
“Imperative” means to give a command, and in imperative programming, the application runs as a series of steps (commands). This is a very broad definition and doesn’t help much - aren’t most programs a “series of steps”? Where it matters though is what it implies about imperatively derived state, specifically that it is not actually derived state (at least, as defined in the previous section).
Let’s take a look at the first example again, and derive the value of aPlusB imperatively. Rather than defining a function that can be called to get the value at any time, we’ll instead derive the value manually in a few steps:
- Create a new variable (a new root state).
- Assign it to the value of
a + b.
let a = 1;
let b = 2;
let aPlusB = a + b;At first, this example may appear to be much simpler than the previous one, as we’re only assigning one more variable in one more step. But the complexity comes when we want to update a or b. Since aPlusB is its own root state, we must now update it as well:
let a = 1;
let b = 2;
let aPlusB = a + b;
// update `a`
a = 4;
aPlusB = a + b;
// update `b`
b = 7;
aPlusB = a + b;Because we created a new root state imperatively, we must now always keep that root state in sync with the other state imperatively as well. Every time you command the computer to update a, you must also command it to update aPlusB. For a more concrete example, you could imagine a component API that forced you to manually rerender whenever you changed a value:
export default class Counter extends Component {
count = 0;
@action
incrementCount() {
this.count++;
this.rerender();
}
}This would be a lot to remember, and could easily introduce bugs and errors if rerender() was called in the wrong way, or at the wrong time, or not called at all. The core issue here is that both of these designs require a command to tell them to update each time something changes.
By contrast, “declarative” programming does not force the user to manually sync things up every time. Let’s consider the original example for aPlusB() again.
let a = 1;
let b = 2;
function aPlusB() {
return a + b;
}In this design, instead of assigning the value to a new variable which we have to update, we create a function that derives the value. Effectively, we are describing the “how” once, so that we never have to do it again. Instead, everywhere else in our code, we can call aPlusB() and know that we will get the right result. We can declare the values that we want to use, and then declare how they should interact with their surroundings.
This is what makes templates in frameworks like Ember, Vue, and Svelte so powerful, and (if perhaps to a lesser extent) what makes JSX feel better than manually returning the function calls that JSX compiles down to. HTML is fundamentally a declarative-only programming language - you can’t tell the browser how to render, you can only tell it what to render. By extending HTML, templates are in turn extending that declarative paradigm, and modern frameworks use that as the basis for their reactivity. The “what” that programmers are describing is, in the end, DOM, and frameworks figure out how to translate your app’s state into that DOM, without you ever needing to worry about it.
What About FP?
There are many different ways to accomplish declarative programming. You can use “streams” and “agents” and “actors”, you can use objects or functions or a mixture of both. You can create your own language, such as HTML, that is purely declarative, and many UI systems have done this in the past because of how well it works in general.
One such way is functional programming (or FP), which has been very much in vogue recently for a variety of reasons. In what is known as “pure” functional programming, no new root state is ever introduced or changed when calculating a value - everything is a direct result of its inputs.
let a = 1;
let b = 2;
function plus(first, second) {
return first + second;
}
// to get a + b;
plus(a, b);In the most extreme form of this model, state for the entire application is fully externalized and then fed into the main function for the app. When state is updated, you run the function again with the new state, generating the new output.
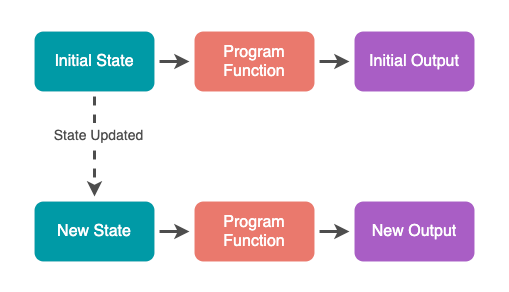
This may seem like an expensive strategy, but there are ways to reduce the cost (we’ll get more into that in the next post). What’s important here is that pure FP is necessarily declarative, because everything boils down to a function that receives an input and produces an output, without making any changes. This means there’s no wiggle room for imperative steps that can cause things to be out of sync.
This is one of the reasons why people like functional programming. It is a very strict form of programming, but it has a lot of benefits that come with that strictness, declarative-ness being one of them.
In the end, though, declarative programming is not limited to functional programming, and so reactivity as a whole is not either. Most reactivity systems end up being a blend of abstractions and paradigms, with some leaning more toward a “pure” FP style and others leaning into Object-Oriented Programming on some level (for instance, actor-based systems ultimately store state per-process, which isn’t all that different from OOP. Check out the history of the term “message-passing” to see some more similarities!). What every reactive system has in common though is declarative-ness.
Summing Up
So, in this post we learned:
“Reactivity” roughly means “a declarative programming model for updating based on changes to state”. This definition probably wouldn’t pass academic muster, but it’s the definition I’m going with for this series at least!
“State” means all of the values that can change in a program. There are two types of state (again, for the purposes of this series):
- Root state, which are actual values stored in variables, in arrays, or on objects directly.
- Derived state, which are values that are derived from root state via getters, functions, templates, or other means.
“Declarative programming” means a style in which the programmer describes what they want their output to be, without describing how exactly to do it. HTML is an example of a purely declarative programming language, and functional programming is a style that ensures code is declarative. There are many ways to write declarative programs, libraries, and frameworks using every programming paradigm.
Next time we’ll dig into a number of different reactivity models at a high level, and discuss what the properties of a good reactive system are. We’ll discuss, in particular, how it is possible to make reactive systems which incorporate object-oriented and imperative code, while still fundamentally being declarative. And we’ll discuss where the pitfalls of those styles are, and how user’s can “break” declarative-ness in some cases.